Magic Text Extractor!

What's OCR?
Retyping characters on a great deal of data-locked documents make most people who have to do this exhausted, they want to find a method out which can extract text with less effort. That method should allow them to get the content easily without reloading manually which waste a lot of time and often makes mistakes (Always we must come back to check errors).
Naturally, after stumbled across the problem, we right now begin to think of the technology OCR! What else? It is the best method to extract text at real-time.

OCR, which stands for "Optical Character Recognition" is a technology that can ease workload thus save your previous time when working with such type documents, data-locked PDF files, text-based scanned pages, even images with text content from digital camera and so on, after real-time OCRing, you can extract the characters from those un-editable files into TXT or DOC form for later use or edit.
How the OCR tools work?
OCR tools can capture text from PDF documents, scanned files or all major formats images like bmp, tiff, jpg, gif, png, etc and then save the extracted text into word doc, TXT or even html. The tools always adopt Matrix Matching or Feature Extraction method to grab the data-locked text. Well, Matrix Matching is a form of pattern matching with which OCR software looks at a character and matches it to one in its library of characters or character templates. Feature Extraction does not rely on a predefined library, but on general features such as open areas, closed shapes, and intersecting lines when deciphering characters. Feature Extraction also goes by the name Intelligent Character Recognition, or ICR.
Using OCR tools, you can easily extract all text content from those un-editable documents.
Search OCR Software on Internet
There are several OCR software solutions available to extract text from the scanned images, Word, Excel, HTML or searchable PDF. You can choose a good OCR tool through below features:
1. Character recognition accuracy;
2. Page layout reconstruction accuracy;
3. Multi-engine voting technology;
4. Support for languages;
5. Support for searchable PDF output;
6. Speed;
7. User interface;
8. Special features for niche projects.
Compare the difference between them. See which performs best with your documents. Because of the infinite combinations of document types, OCR engines, complexity of operations, speed and finally accurate, it may be possible that one engine may perform better with your particular documents but only extract one language and another give an accurate output text but slowly. It’s a difficult choice for you!
Of course, there is another important parameter while choosing OCR software: cost. Why some OCR software cost about $100 while others cost $500 or more? Is there any efficient, accurate and inexpensive tool among these OCR programs?
Just imagine if there is a OCR program run fast and batch extract a great deal of files, accurate output text and layout structure, support different document and language types, especially, it's free, how wonderful?
Boxoft Free OCR
Boxoft Free OCR is an OCR reader recognizes text characters quite fast on the scanned static nearly all formats of images into editable multinational text documents with accurate text formatting and layout structure. You can scan or photograph your paper-based articles or other important text documents with scanners, digital camera or some software (which can convert the document data-locked to image, you can find a free one on boxoft.com). And then upload them to your PC; launch Boxoft Free OCR to extract text from the images; preview the output text and edit; finally saved as TXT or ZIP files for future use.
It's a fast way to help you extract text from scanned files and nearly all formats of images, and it's 100% free for all users, no matter home users, educational institutions, or even corporate users.

Main Features:
1. Boxoft Free OCR gives you the ability to convert multiple language scanned static images into editable text documents. The language types contain: English, French, German, Italian, Dutch, Spanish, Portuguese and Basque. You can extract text written in above language smoothly; just download the free language file from A-PDF Language Pack.
2. One of the coolest features is the ability to convert digital camera images of text pages into editable text document although this is thicker than scanner-created files because of focus and lighting issues and inconsistencies.
3. The most significant feature of using the Boxoft Free OCR is the elimination of human data enter errors. Boxoft Free OCR read data in speeds that can reach over 200 characters per second. The accuracy rate of it is 99.957 percent, or one characters misread in 40,000, as compared to a human misread rate of one in 300 characters. Automatic check digit validation can bring the OCR accuracy rate to fewer than one in 3,000,000.
Superiorities:
1. Completely free, you don’t need to pay any cent, even later upgrade versions are free too;
2. Batch convert images of text documents to TXT or ZIP (compressing file);
3. High accuracy rate;
4. Support images from scanner or digital camera;
5. Fast and high-efficient;
6. Provides 8 languages: English, French, German, Italian, Dutch, Spanish, Portuguese and Basque.
Tips:Poor quality images with text will result in less accurate OCR documents. Handwritten document, documents containing styled text, older documents, photocopies and most faxed documents do not work well with Boxoft Free OCR.
Video Tutorial
Image Tutorials:
The whole image extracting:
1. Original Image file:

2. Start Boxoft Free OCR to operate with below steps:
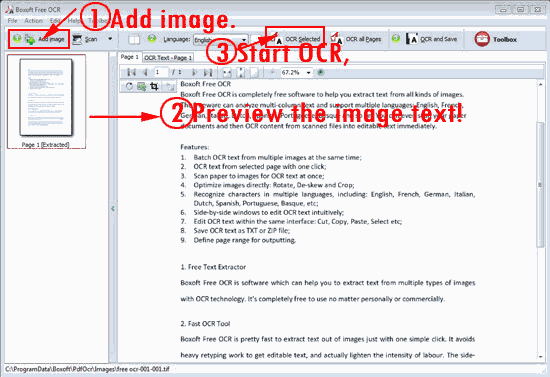
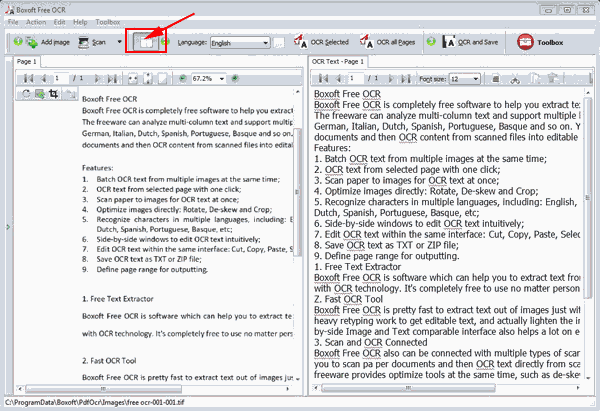
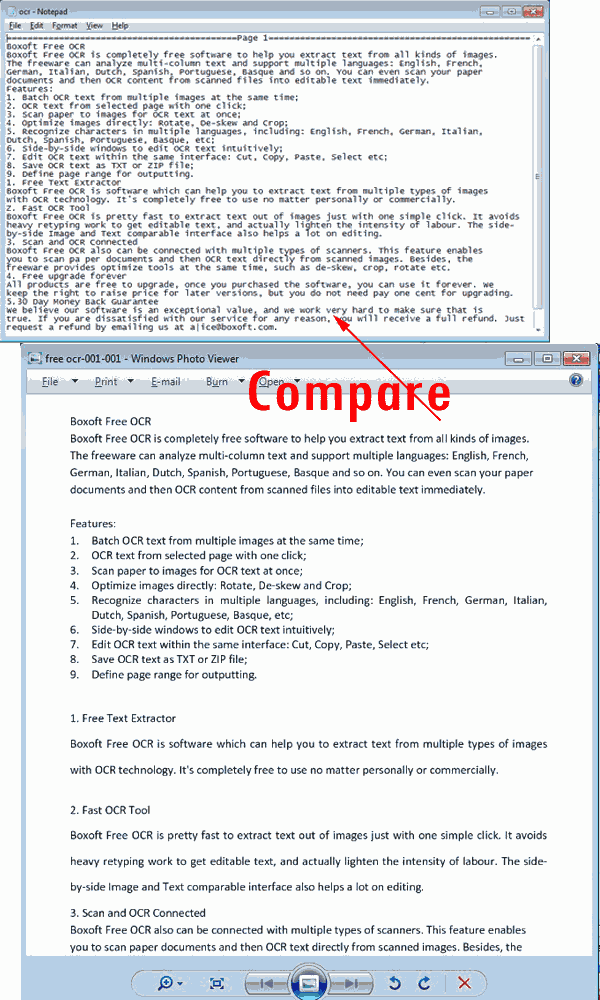
3. Comparision between the original image and the text captured:
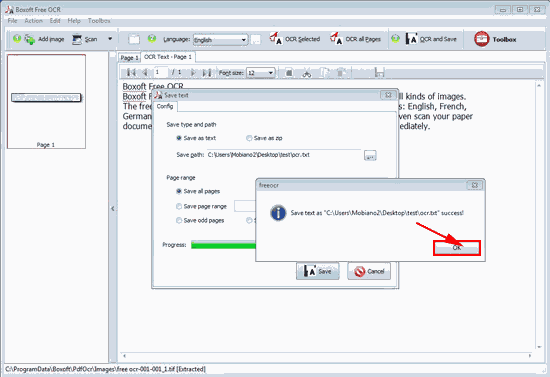
4. Save as TXT format:
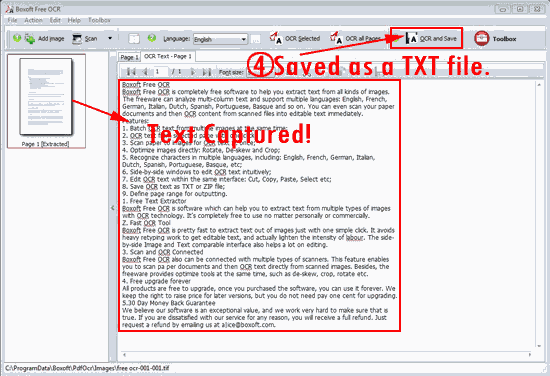
The TXT file comes from the text captured by Boxoft Free OCR: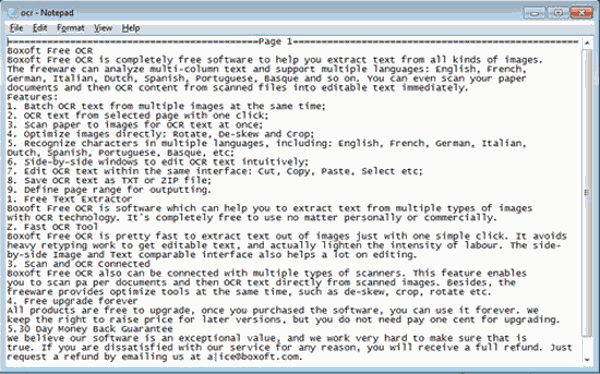
Extracting a portion of the original text image steps below:
1. Click button “Crop”;
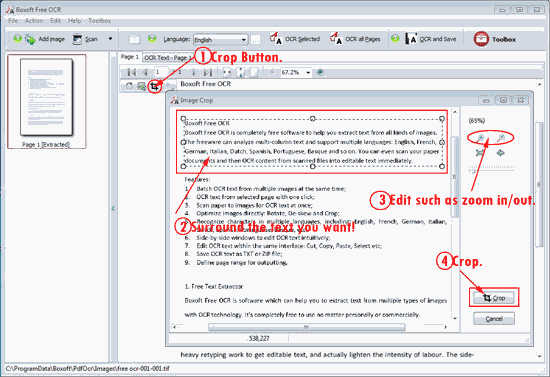
2. Drag your mouse to encircle a paragraph of characters you want;
3. Zoom in/out, display settings: original and fit for editing;
4. Click button “Crop” to tailor the content;
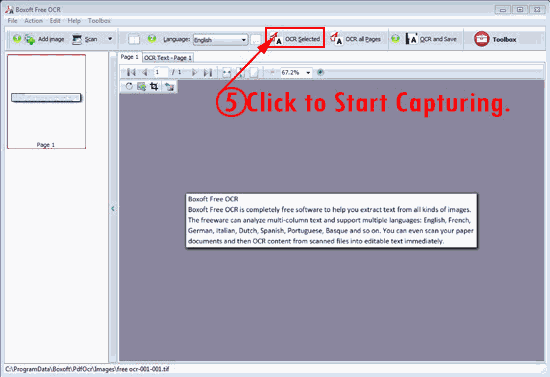
5. Click button “OCR Selected” button to start capturing;
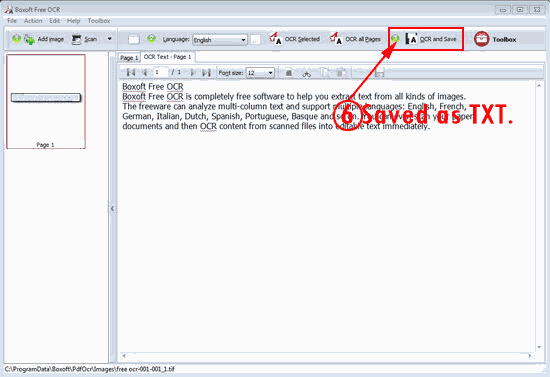
6. Click button “OCR and Save” to save the content as TXT or ZIP;
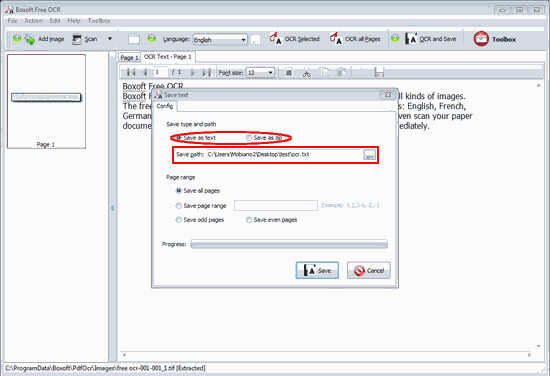
7. Here we check “TXT” and click “Save”, then open the output TXT.
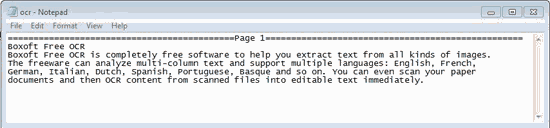
The output captured TXT file, you can carefully check the accuracy comparing with the original image.
Comparison between the original image and output TXT
- Related products
- Boxoft Screen OCR - capture screen and convert screen text into editable electronic text
- Boxoft Free OCR (freeware) - freeware for OCR scanned Image files and converting it into searchable Text

